What is Learning-to-Defer?
What should a model do when it is uncertain: answer anyway, or hand the decision to someone better placed to act? Learning-to-Defer studies exactly this question. Rather than forcing a model to predict on every input, it allows the model to choose between acting and deferring to an expert, a stronger model, or a tool.
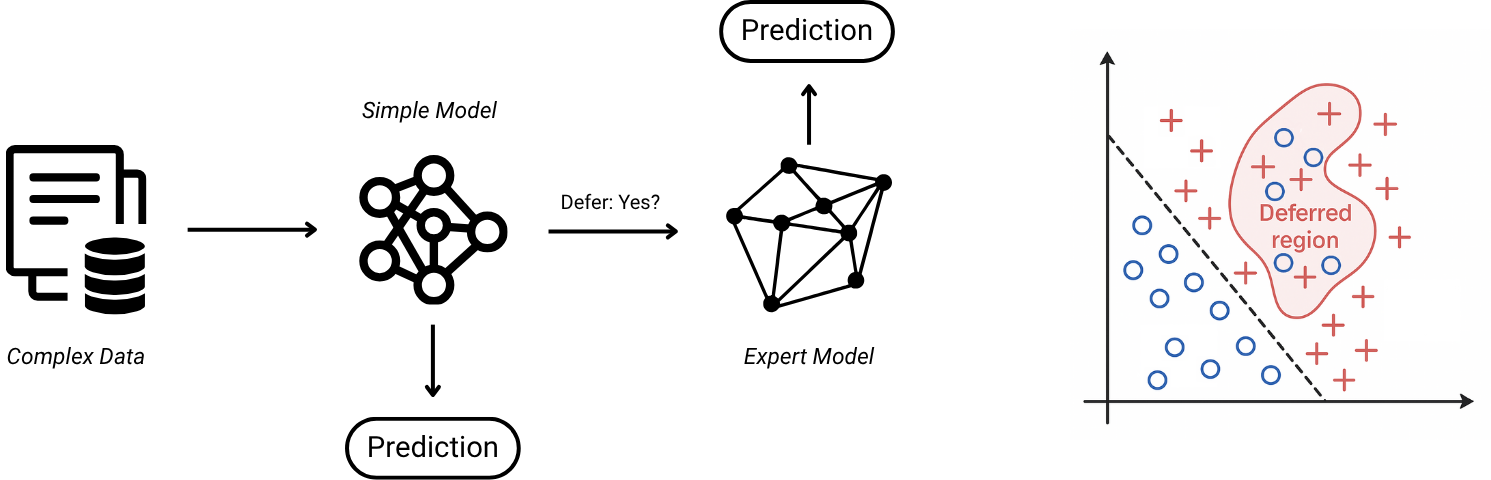
In practice, this turns prediction into a routing problem: for each query, decide whether a lightweight model should respond, or whether the query should be routed elsewhere. The objective is not only accuracy, but also the right balance between risk, cost, and reliability.
Interactive intuition
Where should a model abstain? The toy example below shows a fixed linear decision rule together with a dense mixed pocket in the upper region of the plot.
Draw with your mouse, finger, or pen. Points inside your region are deferred and removed from the accuracy calculation. The goal is to keep coverage high while improving accuracy.
Deferred 0 of 0 points.
My focus
My research studies learning-to-defer from both a theoretical and a practical perspective. I am interested in when deferral rules are statistically well-founded, how to design surrogate losses with formal guarantees, and how these systems behave in more realistic settings: multiple experts, limited feedback, robustness constraints, and changing environments.
More concretely, my work asks questions such as: when should a model defer, to whom should it defer, and how should that decision change when experts have different costs, different strengths, or different availability? These questions appear naturally in human-AI systems, model cascades, and resource-constrained decision pipelines.
Research directions
- Theory: consistency, excess-risk guarantees, and principled learning objectives for defer-or-act decisions.
- Robustness: understanding how deferral systems fail under adversarial or unreliable conditions, and how to make them safer.
- Multi-expert systems: routing among several experts or models, rather than a single fallback option.
- Sequential and constrained settings: handling limited feedback, non-stationarity, or strict compute and latency budgets.
Where it appears
- Healthcare triage: routine cases may be handled automatically, while uncertain or high-risk cases are escalated to a clinician.
- LLM and tool-routing systems: a lightweight model may answer directly, retrieve additional context, or defer to a stronger model or a human.
- High-stakes decision pipelines: when errors are costly, the key question is often not only what to predict, but whether the system should act at all.
Why this matters
- Safer automation: escalation can reduce costly failures when blind confidence is dangerous.
- Better use of expertise: expert time and compute can be allocated where they matter most.
- Explicit trade-offs: accuracy, risk, latency, and cost can be modeled rather than treated separately.
- Principled deployment: theoretical guarantees help clarify when these systems can be trusted and why.
For concrete results and papers, see the Detailed Publications page.